Yali Amit
Professor
Departments of Statistics, Computer Science and the College
Image Analysis
In A Coarse-to-Fine strategy for Multi-class Shape Detection
statistical models for simple scenes of objects are defined as concatenations
of object models, where all edges are assmed independent given
the poses of the different objects in the scene. The marginal
probability at a pixel either given by one of the object models
covering that pixel or by some background probability.
Starting from this model a coarse to fine strategy is developed to
quickly detect candidate object poses. This is based on a
hierarchy of tests for subsets of object classes. The coarse to fine
phase yields a collection of candidate object/pose pairs. Many such pairs
overlap and the ambiguities are resolved with on likelihood ratio
tests derived from the statistical models. These provide an efficient
test for comparing two objects
as well as comparing two competing configurations of objects
covering the same image region. The methodology is applied to
reading license plates on the rear-ends of cars.
Objects are represented through
flexible star type planar arrangements of binary local features,
which are in turn star type planar arrangements of oriented photometrically
invariant edge features.
Candidate locations are
detected over a range of scales and other deformations.
The flexibility of the arrangements provides the required invariance.
Training involves selecting a small number of stable local features,
from a predefined pool,
which are well localized
on {\it registered} examples of the object. Training therefore requires
only small data sets.
Detection is achieved
through
a hierarchical Hough transform. The first level is
for detecting all local features in the image,
the second level for detecting candidate locations for the object.
The features are not
derived from analytic properties of geomteric objects as in classical
Hough transform applications, rather from
local statistics of the training data.
The algorithm is very efficient: 100-300 millisconds per 100x100
pixels on the Ultra Sparc II. Some
detection examples, for more details see
A computational model for visual selection.
A powerful likelihood based approach to recognition is developed in
POP:Patchwork of parts models for shape recognition.
Elementary edge features that ensure photometric invariance,
are assumed independent with
certain marginal probabilities at each location on the grid
given the object is at reference pose. The set of marginal probabilities
assigned to each pixel is called the template probability map.
The edges are assumed independent given other instantiations of the object.
These are described in terms of the locations of a small number of
points of interest with assigned
reference locations at reference pose.
The marginals given a particular instantiation
are obtained by translating subwindows of the probability
maps around the reference locations to the location of the point of interest.
Inconsistencies due to several windows covering a particular pixel are
resolved by averaging the proposed marginals from wach covering window.
This leads to a POP:patchwork of parts model.
Estimation of the templates is also done locally,
estimating the window of probabilies
around each reference point. This can be formulated in a clean
way as a maximum likelihood problem where the translation associated
to each subwindow is unobserved. An EM algorithm is a natural methodology
for computing the maximum likelihood under the observed data.
This model allows us to process images with multiple objects without
pre-segementation. Configurations of single object models are hypothesized
and the most likely configuration is chosen. The use of simple generative models for the objects enables the computation of the likelihood of object configurations.
Randomized decision trees
An approach to shape recognition
using
collections of randomized relational classification trees.
The questions used to split the trees nodes on the training
data involve
global geometric arrangements of image tags,
described in terms of relational graphs.
The tags convey information about local subimage configurations.
At each tree node a huge family of admissible queries is defined,
and only a small random sample is investigated to find
the best one in terms of the drop in the conditional entropy of the distribution on classes.
This randomization allows for the construction of a collection of weakly correlated
trees. Classification of a test image is obtained by finding the mode of the sum of
the terminal distributions on the classes reached by the image in each of these trees.
These relational decision trees have been applied to
handwritten character recognition, where classification
rates of over 99% were achieved on the NIST database.
For further details see
Recognizing shapes from simple queries about geometry
.
A thorough investigation into the properties of this algorithm in the presence
of hundreds of shape classes and connections to brain function are described in
Shape quantization and recognition with randomized
trees
.
Currently
we are exploring extensions to
gray level images of 3d objects and to face
identification in complex scenes.
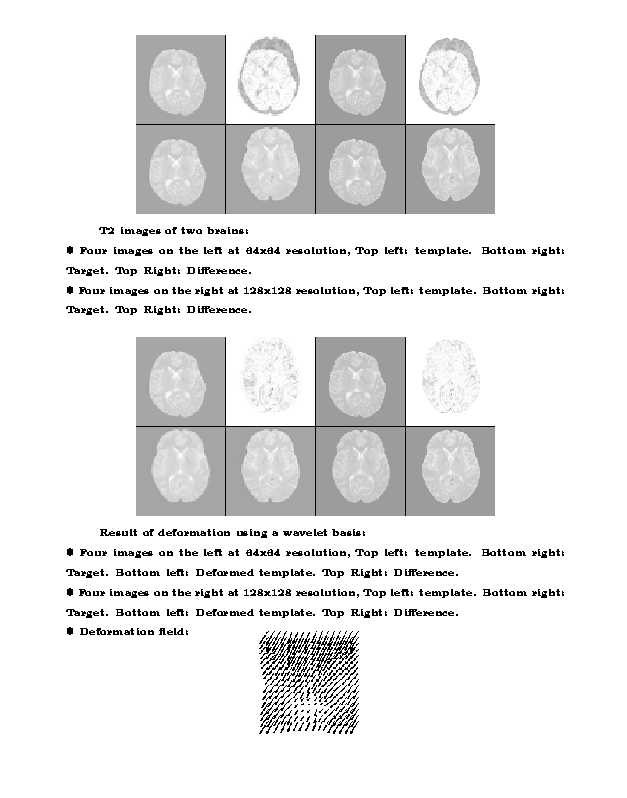
Deformable Templates
These algorithms compute a smooth displacement field in two or
three dimensions which is applied to a prototype image
to yield a warped image as close as possible to some target image
from the same image family.
This has been applied to families of medical images:
2-d hand xrays,
echocardiograms,
2-d MRI scans of the brain,
and 3-d MRI scans.
The computations involve the solution of a non-linear variational
problem using spectral methods.
Example: Matching of axial MRI brain scans of two patients
For further details see
A non-linear variational
problem for image matching.
For the applications of similar ideas in the context of
emission tomography for the identification of tumors,
see
Deformable template models for emission tomography .
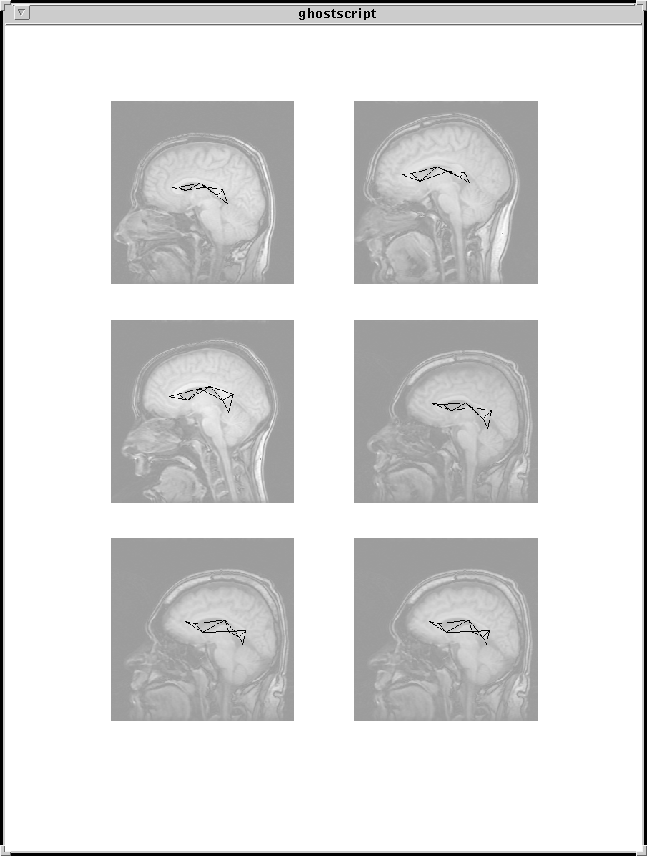
A prior distribution or cost function is defined on deformations
of a graphical template of landmarks constructed from triangles, which penalizes deviations of
shape of these triangles.
A simple likelihood of the data given the landmark locations is formulated,
using robust local operators. An image is scanned for candidates
of each of the landmarks. The algorithm picks out the collection
of candidates
for which the penalty of the match is minimal using
dynamic programming on decomposable graphs.
This approach yields precise matches of landmarks of interest,
and provides an object specific parameterization of shape variation.
It provides a generic
toolbox for modeling shape in a variety of applications.
These models have been applied to hand xrays and different views
of MRI brain scans and provide a means for automatic anatomy
identification.
See image above.
Example: sagittal MRI brain scans
For further details see
Graphical templates for model
registration
.
Graphical shape templates for automatic anatomy
identification with applications to MRI brain scans
.
The methodologies developed above, in particular the use of
photometric invariant features and generative models for the
objects, enables us to detect and track
objects in biological imaging. Confocal microscopy of vesicle dynamics
in cells and the movement of worms even when the worms coil.
Network models for the biological visual system
A network architecture for invariant object detection mimicking the
detection algorithm described above , together with connections
to the biological visual system is discussed
in
A neural network architecture for visual selction. Invariant detection of an invoked object model
is based on a replica module with multiple copies of the inputs.
In Attractor networks for shape recognition
an architecture for learning and recognizing multiple shapes uses a simple
two layer network with inputs given by a small collection of predefined
edge arrangements and second layer
composed of large numbers of neurons with randomly chosen
sub-populations representing each class. Connections from the input to the
output layer are random as are connections within the output layer.
Learning is Hebbian with positive synapses and a field dependent learning
rule that stops potentiation when the local field of the neuron is too high.
The random connections within the output layer are trained and lead to
an attractor dynamic within that layer. Classification is given by the
sub-population that remains active after presentation of the input and
the convergence of the attractor dynamic to a stable state.
Recently in Recurrent network of perceptrons with three state
synapses
we discovered that a slight modification of the above networks yields much more powerful classifiers. Instead of two-state synapses (0/1) connecting the input feature layer to the output layer we use three-state (0/1/2) synapses
together with feed-forward inhibition that makes the effective weights of the synapses (-1/0/1). This small modification allows the learning algorithm to separate
two types of informative features - those that are high probability on class and low probability off class (for which the synaptic state becomes 1), and those
with low probability on class and high probabilty off class (for which the synaptic state becomes -1). All non-informative features end up with synaptic state 0. In addition adding inhibition in the attractor layer allows for stable recurrent dynamics in which the class with most active neurons remains active and all others class neurons are inactivated.
The detection and recognition networks described above are integrated in
An integrated network for
invariant visual detection and recognition.
It is proposed that the replica module (see above) can
be obtained by creating a moderate number of copies of the input layers
and properly wiring their inputs and outputs to the higher modules.
It is proposed that detection and recognition interact
in that detection selects candidate locations and the data from these locations
is passed through the replica module to a
recognition module which can eliminate false detections.
Last update: September 2004
Return to Faculty Research Interests
Return to Yali Amit's Home page
{kind=link}
{kind=link}